I've noticed that builds are broken and tests fail a lot more often on open source projects than on “work” projects. I wasn't sure how much of that was my perception vs. reality, so I grabbed the Travis CI data for a few popular categories on GitHub1.
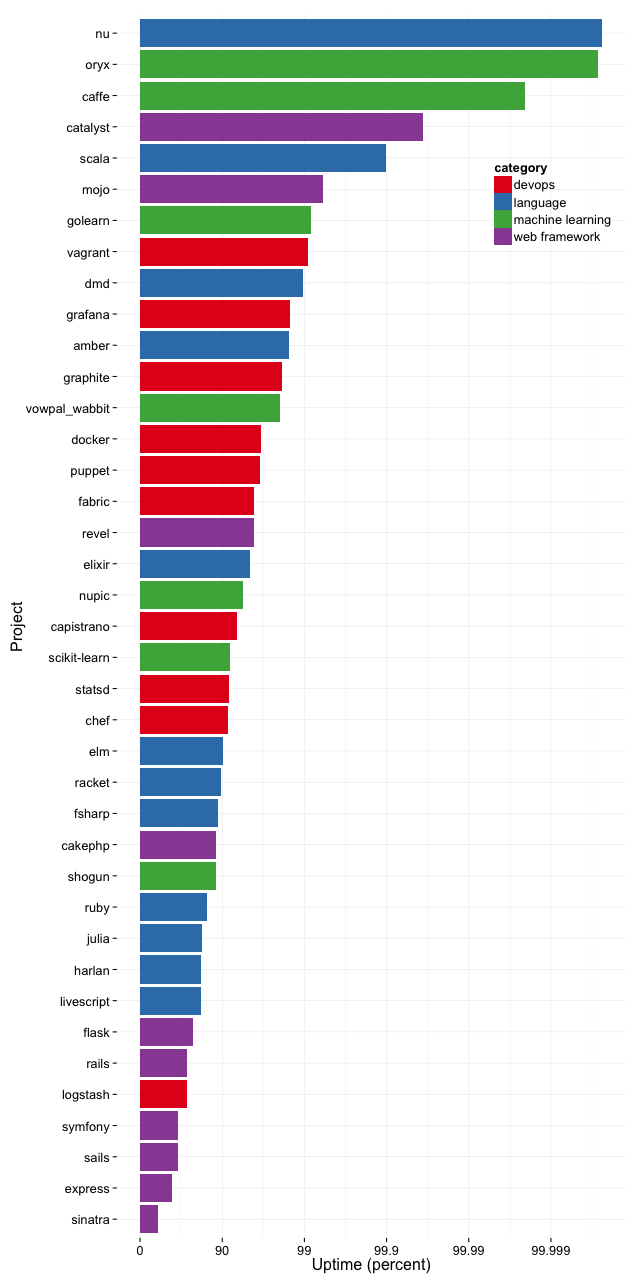
For reference, at every place I've worked, two 9s of reliability (99% uptime) on the build would be considered bad. That would mean that the build is failing for over three and a half days a year, or seven hours per month. Even three 9s (99.9% uptime) is about forty-five minutes of downtime a month. That's kinda ok if there isn't a hard system in place to prevent people from checking in bad code, but it's quite bad for a place that's serious about having working builds.
By contrast, 2 9s of reliability is way above average for the projects I pulled data for2 -- only 8 of 40 projects are that reliable. Almost twice as many projects -- 15 of 40 -- don't even achieve one 9 of uptime. And my sample is heavily biased towards reliable projects. There are projects that were well-known enough to be “featured” in a hand curated list by GitHub. That's already biases the data right there. And then I only grabbed data from the projects that care enough about testing to set up TravisCI3, which introduces an even stronger bias.
To make sure I wasn't grabbing bad samples, I removed any initial set of failing tests (there are often a lot of fails as people try to set up Travis and have it misconfigured) and projects that that use another system for tracking builds that only have Travis as an afterthought (like Rust)4.
Why doesn't the build fail all the time at work? Engineers don't like waiting for someone else to unbreak the build and managers can do the back of the envelope calculation which says that N idle engineers * X hours of build breakage = $Y of wasted money.
But that same logic applies to open source projects! Instead of wasting dollars, contributor's time is wasted.
Web programmers are hyper-aware of how 100ms of extra latency on a web page load has a noticeable effect on conversion rate. Well, what's the effect on conversion rate when a potential contributor to your project spends 20 minutes installing dependencies and an hour building your project only to find the build is broken?
I used to dig through these kinds of failures to find the bug, usually assuming that it must be some configuration issue specific to my machine. But having spent years debugging failures I run into with make check on a clean build, I've found that it's often just that someone checked in bad code. Nowadays, if I'm thinking about contributing to a project or trying to fix a bug and the build doesn't work, I move on to another project.
The worst thing about regular build failures is that they're easy5 to prevent. Graydon Hoare literally calls keeping a clean build the “not rocket science rule”, and wrote an open source tool (bors) anyone can use to do not-rocket-science. And yet, most open source projects still suffer through broken and failed builds, along with the associated cost of lost developer time and lost developer “conversions”.
Please don't read too much into the individual data in the graph. I find it interesting that DevOps projects tend to be more reliable than languages, which tend to be more reliable than web frameworks, and that ML projects are all over the place (but are mostly reliable). But when it comes to individual projects, all sorts of stuff can cause a project to have bad numbers.
Thanks to Kevin Lynagh, Leah Hanson, Michael Smith, Katerina Barone-Adesi, and Alexey Romanov for comments.
Also, props to Michael Smith of Puppetlabs for a friendly ping and working through the build data for puppet to make sure there wasn't a bug in my scripts. This is one of my most maligned blog posts because no one wants to believe the build for their project is broken more often than the build for other projects. But even though it only takes about a minute to pull down the data for a project and sanity check it using the links in this post, only one person actually looked through the data with me, while a bunch of people told me how it must quite obviously be incorrect without ever checking the data.
This isn't to say that I don't have any bugs. This is a quick hack that probably has bugs and I'm always happy to get bugreports! But some non-bugs that have been repeatedly reported are getting data from all branches instead of the main branch, getting data for all PRs and not just code that's actually checked in to the main branch, and using number of failed builds instead of the amount of time that the build is down. I'm pretty sure that you can check that any of those claims are false in about the same amount of time that it takes to make the claim, but that doesn't stop people from making the claim.
- Categories determined from GitHub's featured projects lists, which seem to be hand curated. [return]
- Wouldn't it be nice if I had test coverage data, too? But I didn't try to grab it since this was a quick 30-minute project and coming up with cross-language test coverage comparisons isn't trivial. However, I spot checked some projects and the ones that do poorly conform to an engineering version of what Tyler Cowen calls "The Law of Below Averages" -- projects that often have broken/failed builds also tend to have very spotty test coverage. [return]
I used the official Travis API script, modified to return build start time instead of build finish time. Even so, build start time isn't exactly the same as check-in time, which introduces some noise. Only data against the main branch (usually master) was used. Some data was incomplete because their script either got a 500 error from the Travis API server, or ran into a runtime syntax error. All errors happened with and without my modifications, which is pretty appropriate for this blog post.
If you want to reproduce the results, apply this patch to the official script, run it with the appropriate options (usually with --branch master, but not always), and then aggregate the results. You can use this script, but if you don't have Julia it may be easier to just do it yourself.
[return]- I think I filtered all the projects that were actually using a different testing service out. Please let me know if there are any still in my list. This removed one project with one-tenth of a 9 and two projects with about half a 9. BTW, removing the initial Travis fails for these projects bumped some of them up between half a 9 and a full 9 and completely eliminated a project that's had failing Travis tests for over a year. The graph shown looks much better than the raw data, and it's still not good. [return]
Easy technically. Hard culturally. Michael Smith brought up the issue of intermittent failures. When you get those, whether that's because the project itself is broken or because the CI build is broken, people will start checking in bad code. There are environments where people don't do that -- for the better part of a decade, I worked at a company where people would track down basically any test failure ever, even (or especially) if the failure was something that disappeared with no explanation. How do you convince people to care that much? That's hard.
How do you convince people to use a system like bors, where you don't have to care to avoid breaking the build? That's much easier, though still harder than the technical problems involved in building bors.
[return]